what pieces of information are required to calculate a z-statistic?
A z-score measures the altitude between a information signal and the mean using standard deviations. Z-scores can be positive or negative. The sign tells you whether the observation is above or beneath the mean. For example, a z-score of +2 indicates that the data point falls two standard deviations in a higher place the mean, while a -2 signifies it is two standard deviations beneath the mean. A z-score of zero equals the mean. Statisticians also refer to z-scores equally standard scores, and I'll use those terms interchangeably.
Standardizing the raw data past transforming them into z-scores provides the post-obit benefits:
- Understand where a data indicate fits into a distribution.
- Compare observations between dissimilar variables.
- Place outliers
- Calculate probabilities and percentiles using the standard normal distribution.
In this post, I cover all these uses for z-scores along with using z-tables, z-score calculators, and I show you how to practice it all in Excel.
How to Find a Z-score
To calculate z-scores, take the raw measurements, subtract the hateful, and divide by the standard deviation.
The formula for finding z-scores is the following:
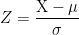
X represents the information point of interest. Mu and sigma represent the mean and standard deviation for the population from which you drew your sample. Alternatively, employ the sample mean and standard deviation when yous do not know the population values.
Z-scores follow the distribution of the original data. Consequently, when the original information follow the normal distribution, so do the respective z-scores. Specifically, the z-scores follow the standard normal distribution, which has a hateful of 0 and a standard deviation of i. Still, skewed data will produce z-scores that are similarly skewed.
In this postal service, I include graphs of z-scores using the standard normal distribution because they bring the concepts to life. Additionally, z-scores are most valuable when your data are normally distributed. Withal, be aware that when your data are nonnormal, the z-scores are also nonnormal, and the interpretations might not exist valid.
Learn how to identify the distribution of your data!
Related posts: The Mean in Statistics and Standard Departure
Using Z-scores to Understand How an Observation Fits into a Distribution
Z-scores help you sympathize where a specific observation falls within a distribution. Sometimes the raw test scores are not informative. For case, SAT, ACT, and GRE scores do non have real-world interpretations on their own. An SAT score of 1340 is not fundamentally meaningful. Many psychological metrics are simply sums or averages of responses to a survey. For these cases, you demand to know how an individual score compares to the unabridged distribution of scores. For instance, if your standard score for any of these tests is a +2, that's far higher up the hateful. Now that's helpful!
In other cases, the measurement units are meaningful, merely you want to see the relative continuing. For example, if a babe weighs five kilograms, you might wonder how her weight compares to others. For a one-calendar month-old baby girl, that equates to a z-score of 0.74. She weighs more than average, but non by a full standard difference. Now y'all empathize where she fits in with her cohort!
In all these cases, you're using standard scores to compare an observation to the average. You're placing that value within an entire distribution.
When your information are usually distributed, you can graph z-scores on the standard normal distribution, which is a particular class of the normal distribution. The hateful occurs at the elevation with a z-score of null. In a higher place average z-scores are on the right half of the distribution and below average values are on the left. The graph below shows where the baby's z-score of 0.74 fits in the population.

Analysts often convert standard scores to percentiles, which I cover afterwards in this mail.
Related postal service: Understanding the Normal Distribution
Using Standard Scores to Compare Unlike Types of Variables
Z-scores permit you to take data points drawn from populations with different means and standard deviations and place them on a mutual scale. This standard scale lets you compare observations for unlike types of variables that would otherwise be difficult. That's why z-scores are also known equally standard scores, and the process of transforming raw data to z-scores is called standardization. It lets you lot compare data points across variables that have different distributions.
In other words, you lot can compare apples to oranges. Isn't statistics m!
Imagine we literally demand to compare apples to oranges. Specifically, we'll compare their weights. We have a 110-gram apple and a 100-gram orange.
By comparing the raw values, it's piece of cake to see the apple weighs slightly more than the orangish. However, let's compare their z-scores. To practice this, we need to know the means and standard deviations for the populations of apples and oranges. Assume that apples and oranges follow a normal distribution with the following properties:
| Apples | Oranges | |
| Mean weight grams | 100 | 140 |
| Standard Departure | 15 | 25 |
Let's calculate the Z-scores for our apple and orange!
Apple = (110-100) / 15 = 0.667
Orangish = (100-140) / 25 = -i.half-dozen
The apple tree'due south positive z-score (0.667) signifies that it is heavier than the average apple. It's not an farthermost value, simply it is above the hateful. Conversely, the orange has a markedly negative Z-score (-1.6). Information technology'south well below the mean weight for oranges. I've positioned these standard scores in the standard normal distribution beneath.

Our apple is a bit heavier than average, while the orangish is puny! Using z-scores, we learned where each fruit falls inside its distribution and how they compare.
Using Z-scores to Observe Outliers
Z-scores can quantify the unusualness of an observation. Raw data values that are far from the average are unusual and potential outliers. Consequently, we're looking for high absolute z-scores.
The standard cutoff values for finding outliers are z-scores of +/-three or more than extreme. The standard normal distribution plot below displays the distribution of z-scores. Z-scores beyond the cutoff are so unusual you lot tin can inappreciably run across the shading under the curve.

In populations that follow a normal distribution, Z-score values exterior +/- three have a probability of 0.0027 (2 * 0.00135), approximately 1 in 370 observations. Notwithstanding, if your information don't follow a normal distribution, this approach might not exist correct.
For the example dataset, I display the raw data points and their z-scores. I circled an ascertainment that is a potential outlier.

Caution: Z-scores can exist misleading in small datasets because the maximum z-score is limited to (n−1) / √ n.
Samples with ten or fewer data points cannot accept Z-scores that exceed the cutoff value of +/-3.
Additionally, an outlier's presence throws off the z-scores because it inflates the mean and standard deviation. Notice how all z-scores are negative except the outlier'south value. If we calculated Z-scores without the outlier, they'd be unlike! If your dataset contains outliers, z-values appear to exist less extreme (i.eastward., closer to zero).
Related mail service: Five Means to Notice Outliers
Using Z-tables to Calculate Probabilities and Percentiles
The standard normal distribution is a probability distribution. Consequently, if you have just the hateful and standard difference, and you can reasonably assume your data follow the normal distribution (at least approximately), you can easily employ z-scores to summate probabilities and percentiles. Typically, you'll employ online calculators, Excel, or statistical software for these calculations. We'll get to that.
Merely first I'll show y'all the one-time-fashioned fashion of doing that by hand using z-tables.
Let's go back to the z-score for our apple tree (0.667) from before. We'll utilise it to calculate its weight percentile. A percentile is the proportion of a population that falls below a value. Consequently, we need to find the surface area under the standard normal distribution curve respective to the range of z-scores less than 0.667. In the portion of the z-tabular array beneath, I'll utilize the standard score that is closest to our apple, which is 0.65.

Click here for a full Z-table and illustrated instructions for using it!
Related post: Understanding Probability Distributions and Probability Fundamentals
The Nuts and Bolts of Using Z-tables
Using these tables to calculate probabilities requires that you empathize the properties of the normal distribution. While the tables provide an answer, information technology might non be the answer you need. However, by applying your knowledge of the normal distribution, you lot tin find your answer!
For example, the table indicates that the expanse of the bend between -0.65 and +0.65 is 48.43%. Unfortunately, that's not what we want to know. We need to find the area that is less than a z-score of 0.65.
Nosotros know that the 2 halves of the normal distribution are symmetrical, which helps u.s.a. solve our problem. The z-table tells us that the area for the range from -0.65 and +0.65 is 48.43%. Because of the symmetry, the interval from 0 to +0.65 must exist half of that: 48.43/two = 24.215%. Additionally, the area for all scores less than zip is half (50%) of the distribution.
Therefore, the area for all z-scores upwards to 0.65 = 50% + 24.215% = 74.215%
That'south how y'all catechumen standard scores to percentiles. Our apple is at approximately the 74th percentile.
If you desire to calculate the probability for values falling between ranges of standard scores, summate the percentile for each z-score and then subtract them.
For case, the probability of a z-score betwixt 0.40 and 0.65 equals the deviation between the percentiles for z = 0.65 and z = 0.forty. We calculated the percentile for z = 0.65 above (74.215%). Using the same method, the percentile for z = 0.40 is 65.540%. Now nosotros subtract the percentiles.
74.215% – 65.540% = 8.675%
The probability of an observation having a z-score betwixt 0.40 and 0.65 is 8.675%.
Using merely simple math and a z-table, you lot tin easily find the probabilities that you need!
Alternatively, utilize the Empirical Rule to discover probabilities for values in a normal distribution using ranges based on standard deviations.
Related post: Percentiles: Interpretations and Calculations
Using Z-score Calculators
In this twenty-four hours and age, you'll probably utilise software and online z-score calculators for these probability calculations. Statistical software produced the probability distribution plot below. It displays the apple'south percentile with a graphical representation of the area under the standard normal distribution curve. Graphing is a swell way to get an intuitive experience for what you're calculating using standard scores.
The percentile is a tad different because we used the z-score of 0.65 in the table while the software uses the more precise value of 0.667.

Alternatively, you can enter z-scores into calculators, similar this 1.
If you lot enter the z-score value of 0.667, the left-tail p-value matches the shaded region in the probability plot above (0.7476). The right-tail value (0.2524) equals all values higher up our z-score, which is equivalent to the unshaded region in the graph. Unsurprisingly, those values add to 1 considering you're covering the entire distribution.
How to Notice Z-scores in Excel
Y'all can calculate z-scores and their probabilities in Excel. Permit'south work through an example. Nosotros'll render to our apple tree instance and offset by computing standard scores for values in a dataset. I accept all the information and formulas in this Excel file: Z-scores.
To find z-scores using Excel, you'll need to either calculate the sample hateful and standard deviation or apply population reference values. In this case, I use the sample estimates. If you need to use population values supplied to you, enter them into the spreadsheet rather than calculating them.
My apple weight data are in cells A2:A21.
To calculate the hateful and standard difference, I use the following Excel functions:
- Mean: =AVERAGE(A2:A21)
- Standard difference (sample): =STDEV.S(A2:A21)
Then, in column B, I utilise the post-obit Excel formula to calculate the z-scores:
=(A2-A$24)/A$26
Prison cell A24 is where I have the mean, and A26 has the standard deviation. This formula takes a data value in column A, subtracts the mean, and then divides by the standard deviation.
I copied that formula for all rows from B2:B21 and Excel displays z-scores for all data points.
Using Excel to Summate Probabilities for Standard Scores
Side by side, I use Excel's NORM.S.DIST office to calculate the probabilities associated with z-scores. I piece of work with the standard score from our apple case, 0.667.
The NORM.S.DIST (Z, Cumulative) function provides either the cumulative distribution function (TRUE) or probability mass function (FALSE) for the z-score you lot specify. The probability mass function is the tiptop value in the z-table earlier in this postal service, and it corresponds to the y-centrality value on a probability distribution plot for the z-score. We'll use the cumulative function, which calculates the cumulative probability for all z-scores less than the value nosotros specify.
In the part, we need to specify the z-value (0.667) and apply the Truthful parameter to obtain the cumulative probability.
I'll enter the following:
= NORM.S.DIST(0.667,TRUE)
Excel displays 0.747613933, matching the output in the probability distribution plot above.
If you desire to find the probability for values greater than the z-score, remember that the values above and below information technology must sum to one. Therefore, subtract from 1 to summate probabilities for larger values:
= 1 – NORM.Southward.DIST(0.667,Truthful)
Excel displays 0.252386067.
Here'south what my spreadsheet looks like.

Source: https://statisticsbyjim.com/basics/z-score/
Post a Comment for "what pieces of information are required to calculate a z-statistic?"